AWS GLUE DISCOVERY COMPONENTS
(Databases, Tables, Connections, Crawlers And Classifiers)
Welcome to Part 2!
In the Part 2 - AWS Glue Discovery Componets - of this ETL Train The Trainer workshop, you will understand the AWS Glue Data Catalog and all the Glue resources associated with it.
At first, you will explore all the Glue resources created for you as part of the CloudFormation Template. Then, you will create and run couple more Glue Resources that will be required for the subsequent parts of the workshop.
The Glue components that you work with during this lab include Glue Databases, Tables, Connection, Crawlers and Classifiers.
1. Understanding the Glue Resources Provided (CloudFormation Resources)¶
To browse through all the Glue provided resources first go to the AWS Glue Console by searching for it in the AWS Management Console (Make sure you are in the right region where you started the lab!).
In the far left menu of the AWS Glue Console you can access all your resources like Database, Tables, Crawlers, Jobs, etc.
Databases¶
Definition: A database is a set of associated table definitions, organized into a logical group.
To see all your databases, click on Databases. There, you should see 2 databases, the Default - which, as the name suggests, is the default database for Glue in this region - and the glue_ttt_demo_db which is the database where you will be creating and storing all the workshop's tables metadata for all the labs.

Tables¶
Definition: A table is the metadata definition that represents your data, including its schema. A table can be used as a source or target in a job definition.
To see all your databases, click on Tables, under Databases. There, you should see just one table named web-page-streaming-table. This table has been created as part of the CloudFormation template and you will explore this table in details in the subsequent Part 3 - Glue (Studio) Streaming - lab of this workshop.

Connections¶
Definition: A connection contains the properties needed to connect to your data.
To see all your connections, click on Connections, under Databases. There, you should see only one connection named rds-mysql-connection which we will explore and test in the next step of this lab.

Crawlers¶
Definition: A crawler connects to a data store, progresses through a prioritized list of classifiers to determine the schema for your data, and then creates metadata tables in your data catalog.
To see all your crawlers, click on Crawlers. There, you should see 3 crawlers which were created as part of the CloudFormation template:
- ml-bootstrap-crawler : This crawler is to bootstrap a table that is required for the Part 5 - Machine Learning with Glue & Glue Studio Notebooks. You will explore it later.
- ml-sample-cust-crawler : This crawler is to crawl a sample dataset that is required for the Part 5 - Machine Learning with Glue & Glue Studio Notebooks. You will explore it later.
- mysql-rds-crawler : This crawler is to crawl RDS MySQL customer's table. It uses a the above Glue Connection reach the RDS MySQL database instance. You will explore it in the next step.

Classifiers¶
Definition: A classifier determines the schema of your data. You can use the AWS Glue built-in classifiers or write your own.
To see all your classifiers, click on Classifiers, under Crawlers. There is no classifiers created yet but you will be creating one in the third step step of this lab.

2. Testing and running pre-created Glue Resources (Glue Connection & Glue Crawler for MySQL RDS)¶
Now, let's run a Crawler and verify the tables it will create. But first, let's confirm that the connection that the crawler is going to use is working properly.
Click on Connections, then click on the blue name rds-mysql-connection to open the details of that connection.
You can see that the connection has a JDBC URL that points to the tpcds database that you created earlier in the RDS MySQL. The JDBC URL uses the RDS instance's endpoint. The connection also has the right VPC and Subnet configured as well as a Security Group.

Note 1: As part of the CloudFormation template, this Security Group has been added to an Inboud Rule in the RDS Instance's Security Group which allows traffic on port 3306 (MySQL's default port) of the RDS instance.
Click on Connections again, then check rds-mysql-connection connections box and click on Test Connection.
In the pop-up screen, choose the required IAM Role to perform the connection test (AWSGlueServiceRole-etl-ttt-demo). Finally, click on Test Connection.
Note 2: The AWSGlueServiceRole-etl-ttt-demo has been created as part of CloudFormation template and has all the required permissions for all the labs in this workshop.
While the connection test is running, you will notice the following banner at the:

You don't need to wait for it to finish, you can now click on Crawlers and start exploring the mysql-rds-crawler by click on its blue name.

As you can see, this crawler uses the aforementioned Glue Connection to crawl the path "tpcds/customer" which is the database/table that you created and loaded data earlier. From this screen, just click on Run Crawler at the top.
By starting this crawler, you will notice its Status column progressing from Ready -> Starting -> Xmin elapsed -> Stopping -> Ready again.
TIP: This crawler should take about 2-3 minutes to complete so move to the next step (Step3) then come back here in about 3 minutes to verify the results of running the crawler!
At this point, the previous connection test should have already succeeded. You will see a green banner at top saying "rds-mysql-connection connected successfully to your instance.". At the crawler's successfull completion, you should also see, in the Tables added column, that 1 table has been added.

Go to Databases > Tables on the left menu to check the 1 table created. You will see that, apart from the streaming table, there will be another table named rds_crawled_tpcds_customer created in the glue_ttt_demo_db in which Location says "tpcds.customers" and Classification says "mysql".

Explore this table by clicking on its blue name.

3. Creating new Glue Resources (New Crawler & Classifier)¶
While the above mysql-rds-crawler is running (if you followed the previous tip), it is time to create couple more resources in Glue. First is a Glue Custom CSV Classifier.
Create Classifier
To create a classifier, click on Classifiers in the far left menu, then click on Add Classifier. Fill out the details with the following details:
Classifier name: My-Custom-CSV-Classifier
Classifier type: CSV
Column delimiter: Comma (,)
Quote symbol: Double-quote (")
Column headings: Has headings
(headings list): c_full_name,c_email_address,total_clicks
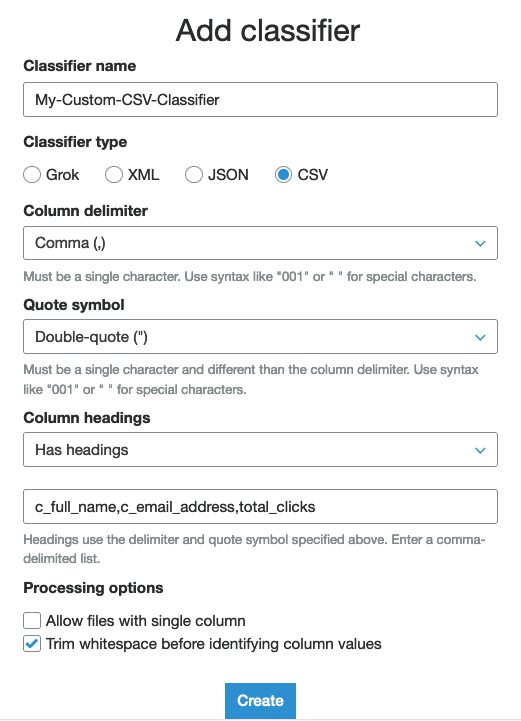
Click on the Create button at the bottom of pop-up page. A new classifier will be added to the list of classifiers.
Create Crawler
Next, as an advanced step, you are going to create a new crawler to crawl the path of the future Glue Streaming job's output that you are going to develop in Part 3 - Glue (Studio) Streaming.
To create a crawler, click on Crawlers in the far left menu, then click on Add Crawler. Fill out the details on each screen as following details:
1. On Add information about your crawler page, provide a name for the new Crawler such as crawl-streammed-data. Then, expand the option that says "Tags, description, security configuration, and classifiers (optional)" and scroll to the bottom to see the list of custom classifiers on the right. Click on Add in front of My-Custom-CSV-Classifier. It will appear on the left side as well now. Click Next.
2. On Specify crawler source type page, simply click Next.
3. On Add a data store page, under Include path, write: s3://\${BUCKET_NAME}/etl-ttt-demo/output/gluestreaming/total_clicks/. (Make sure you replace \${BUCKET_NAME})
TIP: This path doesn't exist yet so switch back quickly to your Cloud9 enviroment tab and run the following command to build the full path string that you need. Copy it and paste it in the Include path field above:
echo s3://${BUCKET_NAME}/etl-ttt-demo/output/gluestreaming/total_clicks/
4. Still on Add a data store page, under Sample Size (optional) choose 1. Then, expand where it says "Exclude patterns (optional)" and in the Exclude patterns field add **00001 and hit Next (twice). (Don't miss the 2 asterisks)

5. On Add another data store page, choose No and click Next.
6. On Choose an IAM role page, click Choose an existing IAM role and pick the role AWSGlueServiceRole-etl-ttt-demo, then click Next.
7. On Create a schedule for this crawler page, just click Next.
8. On Configure the crawler's output page, choose glue_ttt_demo_db from the Database dropdown list. Then, expand where it says "Grouping behavior for S3 data (optional)" and check the box "Create a single schema for each S3 path". Click Next.

9. Review everything in the last page and click Finish.
!!! !!! DO NOT RUN THIS CRAWLER YET !!! !!!
You are finished populating, reviewing and setting up new Glue Resources. Go back to the Crawler you let running to explore the rds_crawled_tpcds_customer table it created. Once you are ready you can move on to Part 3 - Glue (Studio) Streaming!